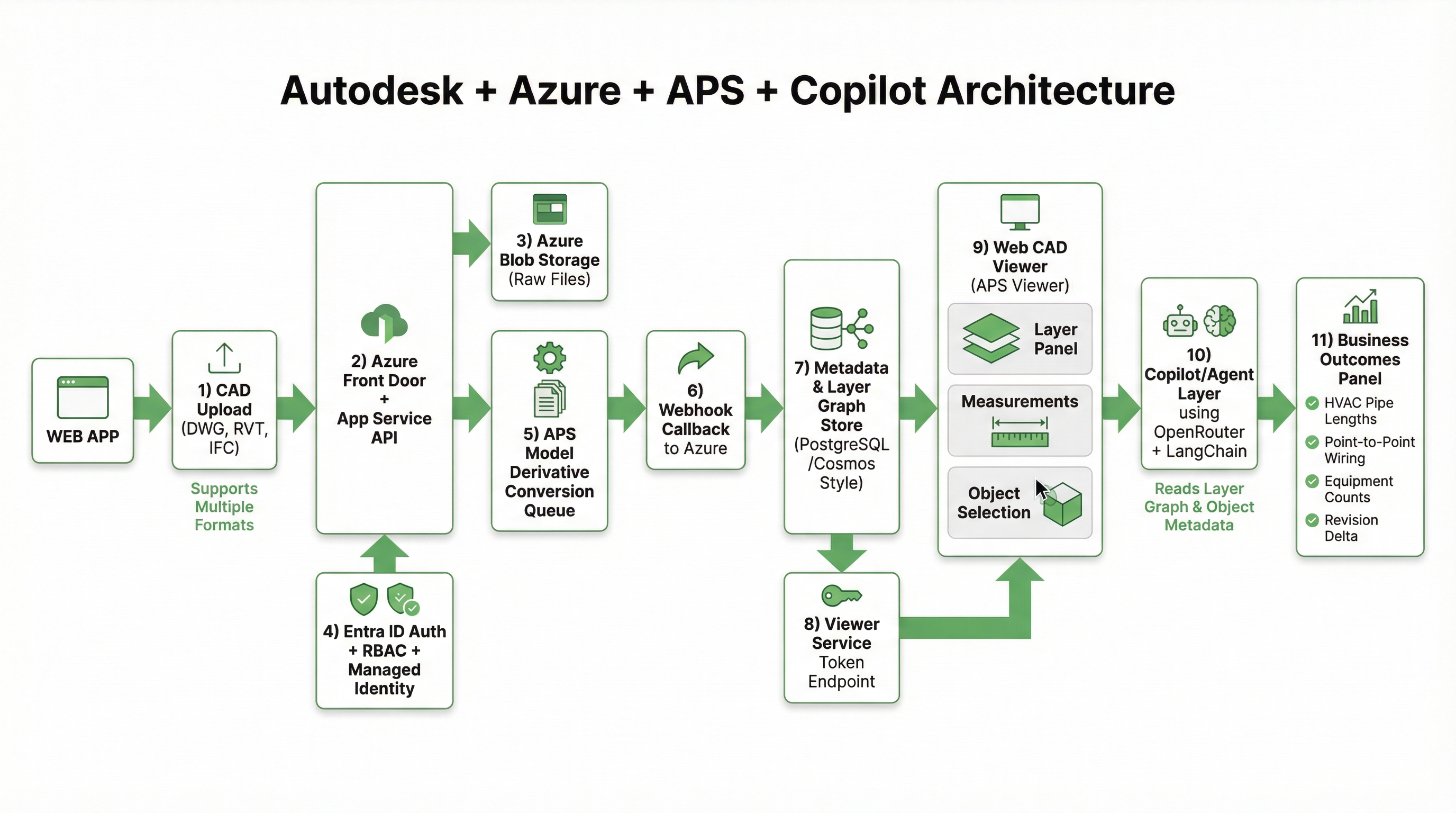
Inside Aginera: Azure Containers, Vercel Frontend, OpenRouter LLM Routing, and Multi-Agent Orchestration
Most people see the polished side of estimating software: upload a plan set, get quantities, generate a quote.
The harder question is: how do you build an architecture that makes that flow reliable at scale, while still being fast enough for real tender timelines?
This post shares how we architect Aginera at a high level: what runs where, how extraction and agent workflows connect, and why we made certain tradeoffs.
We will keep this intentionally practical and useful without exposing implementation details that would weaken our competitive edge.
The product problem we are solving
Aginera is built for one core reality:
- project inputs are unstructured
- teams operate under deadline pressure
- decisions must be auditable, not just fast
A modern stack for this cannot be "one model call and done." It has to support:
- Document ingestion (PDF/CAD and related files)
- Knowledge extraction (quantities, patterns, scope signals)
- Workflow orchestration (multi-step agent execution)
- Commercial output (BOQ, estimate, RFQ, quote, bid/no-bid support)
Layer 1: Frontend delivery on Vercel
The frontend is deployed on Vercel and optimized for rapid iteration and global responsiveness.
Why Vercel for this product
- Fast global edge delivery for the marketing + app shell
- Strong Next.js integration for route-level rendering control
- Reliable CI/CD flow for high-frequency UI updates
Frontend responsibility boundary
The frontend is not used for heavy extraction logic. Instead, it handles:
- project/document workflow UX
- estimator/supplier role flows
- task orchestration triggers
- result review and decision interfaces
In other words: the frontend is control and visibility, not compute-heavy interpretation.
Layer 2: Backend services in Azure containers
Our backend stack runs in Azure-hosted containerized services. This gives us controlled runtime behavior for extraction and orchestration workloads that are bursty and CPU-intensive.
Why containers in Azure
- Predictable execution environment across workers/services
- Better control over dependency-heavy PDF/CV tooling
- Easier separation of API, extraction, and background workloads
What this enables
- Isolated worker paths for extraction jobs
- Safe scaling for spikes in document processing
- Operational control over retries, timeouts, and job state transitions
Layer 3: Document intelligence pipeline (PDF to structured knowledge)
This is where the product value starts.
At a high level, the extraction pipeline follows a layered approach:
- Ingest uploaded project documents
- Classify sheet/document types
- Extract structured signals (text-first and/or vision-assisted paths)
- Normalize into product schemas used by takeoff/BOQ/estimate flows
- Score confidence and expose review surfaces in UI
Why layered extraction matters
No single extraction mode is sufficient across real project sets. Some sheets are text-rich. Others are visually dense. Some need hybrid interpretation.
Our architecture allows:
- deterministic parsing where feasible
- vision-assisted extraction where needed
- fallback strategies when confidence is low
This is how we avoid brittle "all-or-nothing" extraction behavior.
Layer 4: OpenRouter as the model gateway
We use OpenRouter as the LLM routing layer in selected AI workflows.
Why this design choice
- decouples application workflows from one model vendor
- gives us routing flexibility by task type
- improves resilience when model behavior or availability changes
Product principle here
We do not treat model calls as the product.
We treat them as one component in a larger workflow with guardrails, context shaping, and post-processing.
That distinction is important: model outputs become useful only when embedded into structured workflow states.
Layer 5: Multi-agent orchestration with LangChain patterns
At the orchestration layer, we apply multi-agent workflow patterns (with LangChain-style coordination) to break complex work into controlled steps.
Why multi-agent instead of one giant prompt
A single monolithic prompt creates hard-to-debug failure modes. We prefer smaller, role-focused steps that can be:
- validated independently
- retried selectively
- audited in workflow context
Typical agentic flow shape
- Context agent builds scoped document/project context
- Extraction agent produces structured candidate outputs
- Validation agent checks integrity, conflicts, and missing fields
- Decision-support agent summarizes commercial implications
Each stage can emit confidence and flags, which is critical for real estimator workflows.
From extraction to commercial workflow: tying it together
The architecture is useful only if outputs actually drive estimator decisions.
In Aginera, extracted knowledge is connected to:
- Takeoff/QTO review
- BOQ reconciliation
- Estimate assembly
- RFQ package issue
- Supplier quote comparison
- Bid/no-bid and pricing guidance workflows
This is where DesignOps and WorkOps concepts come together:
- DesignOps: structure unstructured technical scope
- WorkOps: turn structured scope into operational/commercial decisions
Guardrails and operational philosophy
For AI systems in estimation workflows, reliability matters more than novelty.
Our guardrail principles:
- Prefer explainable intermediate states over opaque outputs
- Keep confidence and exception surfaces visible to users
- Fail safely (fallback paths) instead of pretending certainty
- Make human review a first-class workflow, not an afterthought
What we intentionally do not optimize for
We do not optimize for "one-click magic" demos that collapse under real project complexity.
Instead, we optimize for:
- consistency across heterogeneous document sets
- controlled behavior under revision pressure
- repeatable outcomes across teams, not hero users
Lessons learned building this stack
- Architecture boundaries matter: frontend, orchestration, extraction, and decision surfaces must be clearly separated.
- Model flexibility is strategic: routing through a model gateway reduces lock-in and improves operational resilience.
- Agent decomposition improves reliability: smaller role-specific steps beat all-in-one prompts for production workflows.
- Workflow wins over features: extraction quality only matters if it reaches BOQ, RFQ, and commercial decisions cleanly.
Closing thought
Aginera is not built as "an LLM app."
It is built as a workflow intelligence system where AI, orchestration, and human judgment work together under real project constraints.
That is the architecture we believe will define the next generation of estimating and execution software.
If this architecture perspective is useful, we can publish a follow-up on the operational side: reliability patterns, fallback design, and quality control loops for production agent systems.